NOC in a Box
The Challenge Every NOC Faces
Network Operations Centers handle thousands of tickets monthly, with engineers at different tiers spending hours on repetitive diagnostics and troubleshooting. We’ve been thinking about this problem for a while - how can AI agents meaningfully reduce that time while maintaining or improving resolution quality?
Our Approach: NOC in a Box
We’ve been working on a concept we call “NOC in a Box” (NIAB) - essentially a series of small AI agents that we’ve been trialing with some clients. These agents operate on a loop, monitoring new tickets in ITSM infrastructure (usually ServiceNow) and proactively seeking to identify and provide resolutions. They can also integrate with business systems like Salesforce for customer context and ticket enrichment.
How We Got Here
Like everyone else, we’ve been fascinated by the capabilities offered by today’s modern AI infrastructure. High-quality models are available in various form factors, consumption models, privacy footprints and use case goals. In mid-2024 we toyed with OpenAI’s function calling capabilities, and by late 2024 we wrote an experimental Netbox MCP library over the holidays. We weren’t the only ones thinking this way - NetBox Labs has since released a public version as the community continues integrating traditional infrastructure tools into MCP.
2025 has brought an explosion in agent tooling - DSPy, LangGraph, Dify - alongside developments from companies like ServiceNow, Selector and IP Fabric that enable AI use cases. Our clients increasingly ask us to help build their AI strategies the same way we previously helped drive automation initiatives - starting with small wins, then expanding to advanced workloads as teams gain time back from solving repetitive work.
How It Actually Works
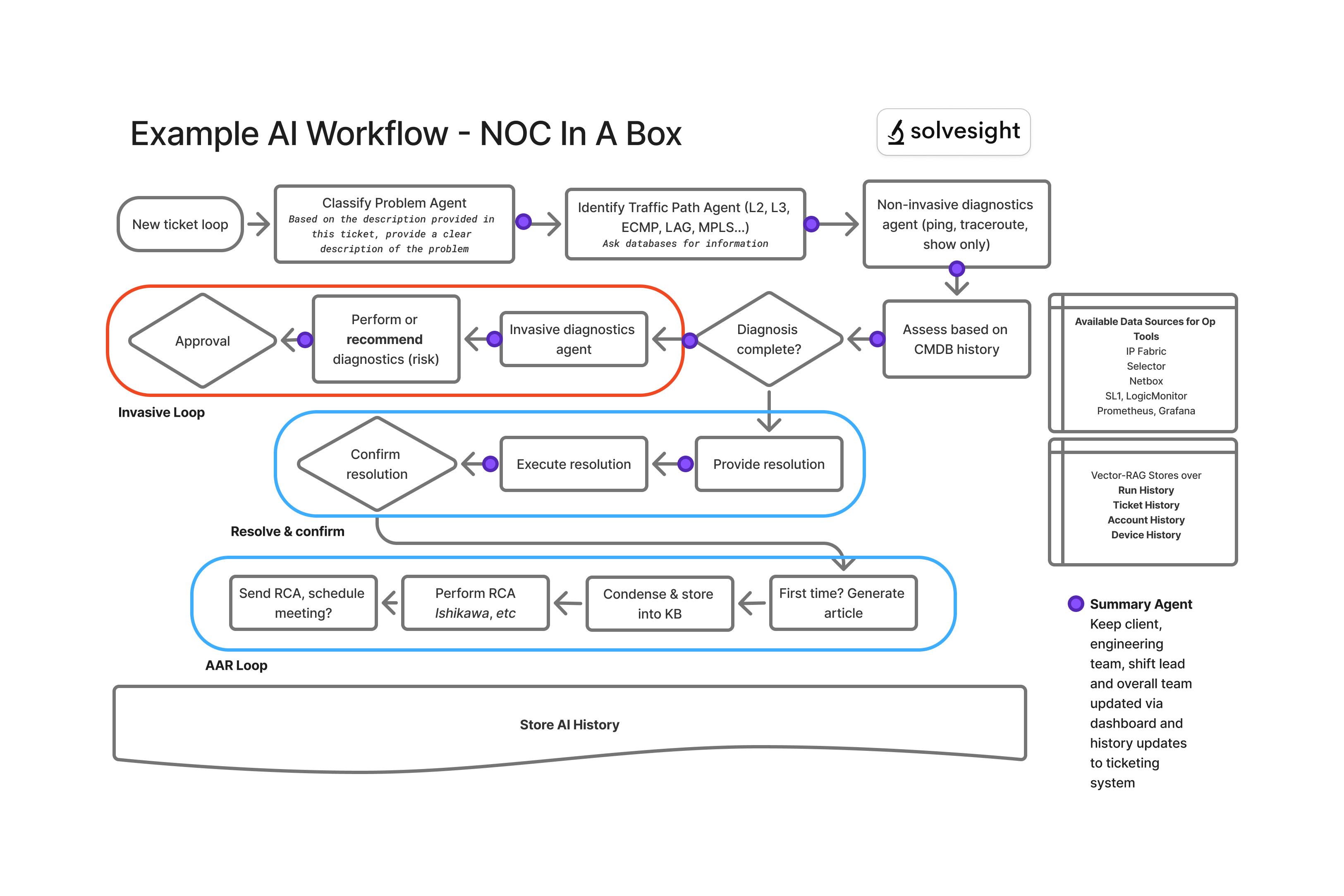
The diagram above looks complex, but think of each “box” and “decision point” as one or more AI agents. They’re all relatively small prompts with structured output guardrails. They log their action history in a vector store (basically a database optimized for AI similarity searches) while also generating human-readable summaries. When needed, they assess traffic paths using tools like IP Fabric, CMDB or traceroute to provide optimal diagnosis.
The agents are mindful of user tiers - a Tier 1 engineer receives different guidance than a Tier 2 engineer, ensuring actions match both skill levels and authorization.
Example Prompts
Here are some very rough example prompts that we might start from. The actual prompts we use for clients differ significantly.
Classify
Based on the included problem description and context, assess if the probability of this being a network problem is greater than X%. Precisely describe possible causes for the network problem and fit them to the format described in FORMAT. Include the context for your assessment and fit it to the format described in CONTEXT.
Diagnostics
Based on the possible causes and context provided, as well as the traffic path, generate a troubleshooting tree that will provide high likelihood of problem diagnosis. Order this troubleshooting tree by descending probability of the test finding the problem.
Troubleshoot
Based on the troubleshooting tree and the tools available to you (NB: MCP tools), determine the cause for the problem and propose a resolution. If you cannot determine a single cause, identify possible causes and propose resolutions for each.
Root Cause
Based on the data available in (context store), carry out the following:
ROOT CAUSE ANALYSIS
- What was the underlying cause of the issue that was fixed
- Why did the system fail in this specific way
- What conditions allowed this failure to occur
- Were there warning signs that were missed
PREVENTION MEASURES
- What safeguards need to be added to prevent recurrence
- What monitoring/alerting gaps need to be filled
- What process changes are required
- What code/configuration improvements should be made
SYSTEM IMPROVEMENTS
- How can detection be improved for similar issues
- What resilience measures should be implemented
- What documentation needs to be updated
- What team knowledge gaps were exposed
VERIFICATION PLAN
- How will you confirm these prevention measures work
- What ongoing monitoring is needed
- When will you review the effectiveness of changes
- What metrics will indicate success
DELIVERABLE
Provide a concise summary of: the true root cause, implemented preventive measures, system improvements made, and the plan for ensuring this type of failure doesn’t happen again. Do not force a “doesn’t happen again” if the problem was transient in nature (e.g. hardware failure).
Why Human Oversight Matters
Since network and security resolutions can be invasive (shut/no shut interfaces, replace optics, etc.), we added human-in-the-loop controls. This proved essential after a popular AI model scared the bejesus out of us by producing this in our lab:
# On Juniper, generate a test syslog message
request system zeroize media-type internal no-confirm
# (Just kidding - don't run that!)For the non-Juniper folks: that command would completely wipe a device’s storage, destroying all configuration and returning it to factory defaults. Definitely not a “test syslog message”! The model understood it needed a Juniper command but selected a catastrophically wrong one. Moments like these remind us why human oversight remains critical.
How We Measure Success
Both agents and humans evaluate whether the summaries match the actions and rate the overall resolutions across multiple dimensions:
- Was the troubleshooting tree of optimal depth (confusion matrix analysis for accuracy)
- Was the CMDB data queried? Used in the final resolution? Would its absence matter?
- Was the troubleshooting structure reasonable for the problem?
- How much of the traffic path was evaluated?
- How many external lookups occurred (against IP Fabric or Netbox)?
- Were shift and org lead summaries meaningful?
- Did the model surprise us, and how?
- How did parallel human execution compare?
Solid evaluations, either subjective or objective, help make “vibes” empirical and drive better outcomes. What’s amazing about a system that logs its inputs and outputs is you can use it for training and education of your staff, plus try new prompts and models against the same ground truth - either in real time or in an environment you can lab out.
Dynamic Lab Generation
One of the most powerful things we’ve been doing with this approach is dynamically creating lab environments based on configurations. Using software tools like containerlab or EVE-NG, hardware tools like Leviton SmartPatch, traffic generators, and NPBs (Network Packet Brokers), we can post-resolution generate similar problem conditions and explore alternative resolutions. This has been a huge boon to OEMs we work with.
Real-World Applications
Regional Service Provider
A regional service provider implemented this approach for their 24/7 NOC operations. Their Tier 1 team now resolves routine connectivity and configuration issues significantly faster, while Tier 2 engineers report meaningful time savings on complex multi-vendor troubleshooting scenarios.
Mid-Sized Manufacturing Enterprise
A mid-sized enterprise in the manufacturing space deployed these agents to handle their IT/OT convergence challenges. The system handles initial diagnostics for production floor network issues, allowing their limited engineering staff to focus on strategic initiatives rather than repetitive troubleshooting.
The Reality Check
As exciting as these findings and experiments are, it’s important to balance hype with reality. AI models have provided an extremely useful set of tools for some problems, but it’s still early days. This pattern is proving particularly beneficial for clients who want to maximize their engineering talent utilization across support tiers. The capability ceiling continues to rise, and we’re learning something new with each implementation.
Consider a typical NOC scenario: 10 Tier 1 engineers ($65k each) and 5 Tier 2 engineers ($100k each). If this approach reduces time-per-ticket by 45-65%, that translates to roughly 4.5 to 6.5 FTE-equivalents of capacity gained - without hiring. That freed capacity can tackle backlog, improve service quality, or support growth without proportional headcount increases.
Moving Forward
If your organization is thinking about how AI could transform your network operations - or if you’re exploring other AI use cases, infrastructure optimization, network architecture, or automation initiatives - we’d love to talk. Every environment is different, and we enjoy exploring how these concepts and technologies might apply to your specific challenges and opportunities.
Written by
Timothy Brown